- Created by Maria Klostermann Tapdrup, last modified by Oskar Jakobsen on Oct 30, 2023
| Oprindelig kilde | WorkZone - 1442-0818 |
|---|---|
| Forfatter | Modelsekretariatet |
| Oprettet | Aug 31, 2016 |
| Version | 1.2 |
| Ændret | Oct 30, 2023 |
| Sidehistorik |
De generelle modelregler vedrører udformning af datamodellen. Formålet med reglerne er at sikre det niveau af ensartethed i domænemodellerne med hensyn til diagrammering, som er nødvendigt for at kunne etablere en samlet Grunddatamodel.
5.1 Modeller skal udarbejdes som UML-klassediagrammer
Regel
Datamodeller for Grunddata skal beskrives i UML (Unified Modeling Language) version 2.4.1 som UML-klassediagrammer.
Rationale
En samlet og sammenhængende model forudsætter anvendelsen af et fælles modelleringssprog. UML er valgt, fordi det er et internationalt anerkendt modelleringssprog, hvor den overordnede forståelse af måden at relatere elementer til hinanden er fastlagt.
Implikationer
Der skal for alle grunddata udarbejdes UML-klassediagrammer med klasser, attributter, relationer og kardinaliteter samt tilhørende dokumentation. Der er krav om attributkomplethed, således at al den information, der udstilles som Grunddata, skal kunne findes i Grunddatamodellen.
Der henvises til uml.org for yderligere information. Almene UML symboler og notationer forklares ikke yderligere i dette dokument.
5.2 UML-modellen skal organiseres i pakker
Regel
UML-modellen skal organiseres i pakker, med en pakke for hvert forretningsdomæne.
Rationale
En logisk organisering af modellens elementer i pakker gør det mere overskueligt at navngive og referere til elementer.
Implikationer
Hver domænemodel placeres i en UML-pakke. En pakke kan have underpakker. Hvor det er relevant, gøres elementer offentlige (‘public’), således at elementer i andre pakker kan referere til dem. Grunddatasekretariatet sørger desuden for, at der kan refereres til UML-pakker med elementer, som indgår i generelle egenskaber (se kapitel 6), samt til pakker udviklet af ISO, for eksempel standardiserede datatyper (se regel 5.5). Se endvidere fodnote til afsnit 2.1
5.3 Modelentiteter skal genbruges
Regel
Modelentiteter skal genbruges på tværs af Grunddatamodellen.
Rationale
Det er en forudsætning for grunddataprogrammet, at modelentiteter genbruges på tværs af grunddata for at sikre sammenhæng og undgå redundant vedligehold af data.
Implikationer
Som modelansvarlig skal man modellere modelentiteterne for sit eget forretningsdomæne samt sørge for at relatere til modelentiteter i andre forretningsdomæners UML-pakker. Se endvidere fodnote til afsnit 2.1
Eksempler
Hvis for eksempel person-domænet har behov for at modellere “Adresse”, skal modelleringen referere/genbruge («use») den korrekte modelentitet inden for Adresse-domænet
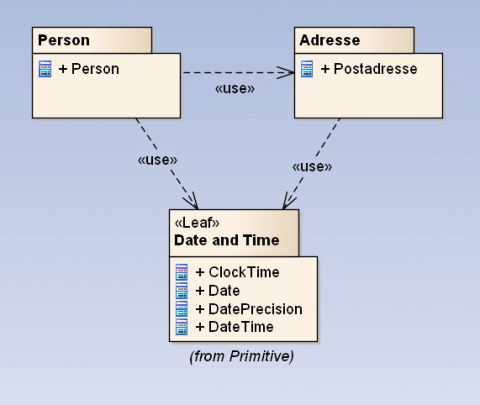
Figur 5 - Pakken “Person” anvender («use») pakkerne “Adresse” og “Date and Time” (fra ISO/TC 211 Harmonized Model) for at anvende klasserne Postadresse og DateTime.
5.4 Attributter og relationer skal modelleres fyldestgørende
Regel
Attributter og relationer mellem UML-elementer skal modelleres fyldestgørende - det vil sige, at attributter modelleres med multiplicitet og datatype, relationer modelleres med multiplicitet, retning og roller.
Rationale
For at modellen skal være entydig samt danne basis for semantisk forståelse af data, er det nødvendigt, at attributterne og relationerne er beskrevet grundigt.
Implikationer
Attributter skal modelleres med en eksplicit type - se regel 5.5 Standardiserede datatyper skal genbruges - samt med multiplicitet det vil sige antalsregler for, hvor mange værdier attributten kan rumme på en enkelt instans af klassen. Relationer (andre end generalisering/specialisering) mellem UML-elementer (associationer, kompositioner, aggregeringer) skal modelleres med navn, læseretning, navigabilitet, navngiven rolle/relations-ende samt multiplicitet (multiplicitet skal ikke angives for generalisering/specialisering). Se endvidere fodnote til afsnit 2.3
Eksempler
På figuren ses hvordan roller, læseretning, navigabilitet og multiplicitet udtrykker en kompleks association mellem to dataobjekter, som ellers ikke vil kunne kommunikeres i regi af modellen.
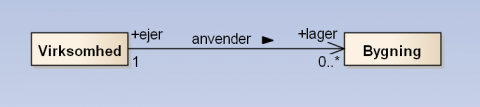
Figur 6 - Virksomhed i rollen som Ejer anvender Bygning som Lager. En virksomhed kan være alt fra lagerløs til lagermonopol (multilagered) - en Bygning kan kun have én ejer.
5.5 Standardiserede datatyper skal genbruges
Regel
Alle attributter skal enten tildeles en standardiseret datatype eller en datatype, der er modelleret som et UML-element i samme eller en anden pakke.
Ved brug af en standardiseret datatype skal der henvises til ISO 19103, hvor en række standardiserede datatyper er samlet og modelleret i UML. ISO 19107 anvendes til geografi.
Rationale
ISO giver en anerkendt ramme for standardiserede datatyper. Anvendelse af en standard for datatyper gør det nemmere at bygge snitflader, der udstiller Grunddata som nemt anvendelige
services.
Implikationer
Standardiserede datatyper i modellen skal hentes fra ISO/TC 211 Harmonized Model.
Denne er en samling af datatyper, som primært anvendes af geografi-relaterede modelleringsprojekter - fx INSPIRE. Ikke desto mindre indeholder ISO/TC 211 Harmonized Model også generelt anvendelige datatyper (CharacterString, Integer, DateTime med videre) modelleret som UML.
Hvis domænet ikke finder typerne i ISO/TC 211 Harmonized Model anvendelige, kan det opbygge sit eget typebibliotek, som skal publiceres sammen med domænemodellen.
ISO/TC 211 Harmonized Model findes frit tilgængelig på adressen https://github.com/ISO-TC211/HMMG, hvorfra den kan importeres i et modelleringsværktøj. Dokumentet “Modelleringsværktøj”, som Grunddatasekretariatet forventes at publicere, vil beskrive anvendelsen af ISO/TC 211 Harmonized Model i detaljer.
5.6 UML-stereotyper skal anvendes
Regel
Alle UML-elementer tildeles en UML-stereotype.
Rationale
På sigt skal det være muligt, at fortolke modellen til andre modeltyper samt fx datasnitflader. UML kan ikke i sig selv udpege elementernes rolle (modelentitet, datatype, enumeration)modellen, hvorfor det er nødvendigt, at udvide modellen med disse roller. UML-stereotyper er udvidelser af modelleringssproget, som gør det muligt at specificere yderligere egenskaber, samt at kategorisere model-elementerne. Med stereotyper kan man udpege specifikke klasser som havende bestemte roller i datamodellen, hvilket igen gør det muligt for et eksternt værktøj, at fortolke modellen til for eksempel datasnitflader og ontologier. Stereotyperne tilføjer roller til ementerne og strukturerer de tagged values, som indeholder dokumentationen af modelelementerne (se Note om tagged values).
Implikationer
Følgende stereotyper anvendes i Grunddatamodellen*:
- «DKObjekttype»: Alle forvaltningsobjekter skal modelleres som UML-klasser med stereotypen «DKObjekttype».
- «DKEnumeration», «DKKodeliste»,«DKKlassifikation»: Attributter med kodede værdier skal modelleres med UML-elementer med stereotyperne
- «DKEnumeration», «DKKodeliste» eller «DKKlassifikation», som værdisæt - se nedenstående NOTE om kodede værdier.
- «DKDatatype»: Attributter, som ikke er kodede værdier og som ikke tildeles en standardiseret datatype fra ISO (se regel 5.5) skal modelleres med en datatype i samme eller en anden pakke, med stereotypen «DKDatatype», som værdisæt. Se endvidere fodnote til afsnit 2.3
- «DKEgenskab»: Attributter og associationsender i Grunddatamodellen har stereotypen «DKEgenskab».
- «DKDomænemodel»: “Rod”-pakken i en afleveret domænemodel markeres med «DKDomænemodel»
Grunddatasekretariatet sørger for, at en UML-profil indeholdende stereotyperne er specificeret. Se http://digitaliser.dk/group/2494445
NOTE om tagged values
UML-elementer kan indeholde ekstra attributter, kaldet tagged values. Ved at anvende tagged values på stereotyperne, kan de på en gang tilføjes alle klasser, der har stereotypen. Disse tagged values kan indeholde specifikke instrukser til det software, som skal fortolke modellen til for eksempel XML schema - se for eksempel INSPIRE GCM afsnit 9.6.3. På nuværende tidspunkt er der ikke overblik over, hvilke instrukser, der er behov for. Disse vil eventuelt kunne tilføjes senere med minimale ændringer af de godkendte modeller. Stereotyperne indeholder tagged values til dokumentation af modellens elementer. Disse dokumentations-tagged values (Definition, Note, Alternativt navn, Lovgrundlag, Eksempel) beskrives i Regel 5.9
NOTE om kodede værdier
Kodede værdier kan modelleres på tre måder:
- «DKEnumeration», hvor værdierne findes eksplicit som en liste i modellen. Bruges typisk, hvor udfaldsrummet er velforstået, og hvor der ikke forventes ændringer hurtigere end modellens overordnede versioneringscyklus gør muligt. Eksempelvis ugedag: {mandag, tirsdag, onsdag, torsdag, fredag, lørdag, søndag}
- «DKKodeliste», hvor værdierne opbevares eksternt, men tilgængeligt på internettet. Se INSPIRE GCM afsnit 9.4.9, 9.5.2 samt Annex G. Dette giver mulighed for dynamisk tilpasning og udvidelse af kodelisten efter behov, samtidig med, at der er et vist mål af styring af historik og proveniens for værdierne.
- «DKKlassifikation», hvor værdierne opbevares i en taksonomi - for eksempel i en klassifikationskomponent, som følger OIO-standarden for Klassifikation. Klassifikationskomponenten kan udstyre værdierne med metadata, opdaterings-metadata og
dobbelthistorik. En klassifikationskomponent indgår i en fremtidig KL/KOMBIT rammearkitektur. Se afsnit 3.3.2.
For enkelte domæner gælder der regler for, hvordan eksterne data styres og håndteres - eksempelvis INSPIRE reglerne, som gælder for nogle af de geodata, som også er grunddata. Sådanne regler kan overholdes samtidig med, at modelreglerne overholdes.
Domænet skal varetage, at de eksterne data, som domænedata refererer til, er tilgængelige og af den fornødne kvalitet. Ligeledes skal domænet overholde de regler, som gælder for arkivering, og som kan tilsige at eksterne data skal kunne afleveres til arkiv sammen med domænedata.
* Modellen kan udvides med domæne-specifikke stereotyper ligesom Grunddata-stereotyperne kan extendes i domænet for eksempel geodatas DKFeaturetype, som extender DKObjekttype
5.7 Navngivningsregler skal følges
Regel
Elementer i UML-modellen skal navngives på ensartet vis i hele Grunddatamodellen. Navngivning skal være entydig inden for domænet - i praksis inden for UML-pakken.
Rationale
En ensartet navnekonvention giver datamodellen et ensartet udtryk og gør det nemmere at identificere og skelne de forskellige klasser af modelelementer fra hinanden.
Implikationer
Klasser og associationer skal navngives entydigt inden for deres pakke.
Klasser, attributter og associationer navngives efter følgende skema:
- Elementer som repræsenterer forvaltningsobjekter (med stereotypen «DKObjekttype»), som er datatyper («DKDatatype»), klassifikationer («DKKlassifikation»), enumerationer («DKEnumeration») eller kodelister («DKKodeliste») navngives med “UpperCamelCase” - det vil sige med stort begyndelsesbogstav i både første ord og alle efterfølgende ord i navnet og uden anvendelse af mellemrum i navnet.
- Attributter, associationer og relationsender navngives med “lowerCamelCase” - det vil sige med lille begyndelsesbogstav i første ord samt stort begyndelsesbogstav i alle efterfølgende ord i navnet og uden anvendelse af mellemrum i navnet *.
NOTE
Af hensyn til modellens anvendelse og transformation i software, som ikke kan håndtere de danske tegn Æ, æ, Ø, ø, og Å, å, kan disse eventuelt translittereres til henholdsvis "Ae, "ae", "Oe", "oe", "Aa" og "aa".
*Hvor navnene består af akronymer kan man fravige denne regel; for eksempel “NUTS1værdi”, “CPRnummer”
5.8 Sprogregler skal anvendes
Regel
Dansk skal anvendes ved navngivning af elementer, som indgår i generelle egenskaber.
Den modelansvarlige fastsætter det sprog, som anvendes ved navngivning af domænets elementer.
ISO-standarder følger deres engelske betegnelser (for eksempel “Integer” og “codeList”).
Datamodellen dokumenteres på dansk, se regel 5.9.
Rationale
Idet grunddata er det offentliges forvaltningsgrundlag, beskrives de som udgangspunkt på dansk, som er forvaltningssproget. Nogle grunddata kan imidlertid være underlagt internationale forpligtelser, som forudsætter brug af andre sprog. For eksempel er en række Grunddata omfattet af EUdirektivet INSPIRE, og skal som følge heraf genbruge UML-elementer, hvor sproget er engelsk. Det er derfor op til den modelansvarlige for domænet at træffe beslutning om sprog for domænespecifikke elementer.
Implikationer
Det er op til den modelansvarlige at vælge sprog for domænets elementer af modellen. Der kan derfor forekomme modeller, hvor der er en blanding af dansk og andre sprog.
5.9 Datamodellen skal dokumenteres
Regel
Datamodellen skal dokumenteres gennem beskrivelser af elementerne i UML-modellen.
Rationale
Dokumentationen gør det muligt for modellens brugere at forstå modellens elementer. Både når man udvikler og anvender modellen, er det essentielt at kommunikere og forstå betydningsindholdet af de enkelte dele af modellen. Det at dokumentationen er indlejret i datamodellen muliggør automatisk dannelse af et katalog over klasser, attributter og relationer. Yderligere kan dokumentationen indgå i datasnitfladerne, hvis der er ønske herom.
Implikationer
Modellens klasser og deres attributter beskriver forretningsobjekter og deres egenskaber, ligesom de roller, objekterne har i forhold til hinanden beskrives som roller/relationsender i hver ende af af en association. Disse forretningsobjekter, egenskaber og roller skal beskrives i
overensstemmelse med den begrebsmodellering, der er i domænet.
Dokumentation i UML med tagged values
Klasser, attributter og roller/relationsender dokumenteres ved brug af tagged values (se Note om tagged values), som specificeret i tabellen nedenfor. De enkelte tags i dokumentationen modsvarer i videst muligt omfang vidensmodelleringsvokabulariet SKOS. Denne strukturerede måde at dokumentere på, muliggør fleksibel generering af tekstdokumentation på baggrund af modellen, ligesom dokumentationen med stor præcision kan transformeres ind i datasnitflader og afledte modeller.
| Tagged values som bruges til dokumentation i datamodellen: | |||
|---|---|---|---|
| Tag definition | SKOS-ækvivalent | Krav | Indhold |
| definition | skos:definition | Krævet | Objektets/egenskabens/rollens definition. Kort tekst, som entydigt beskriver objektet/egenskaben/rollen -kan også indeholde et afsnit med en længere beskrivelse, fx formål, referencer og kilde. |
| note | skos:note | Valgfri | Uddybende beskrivelse af objektet/egenskaben/rollen |
| alternativtNavn | skos:altLabel | Valgfri | Andre navne, som objektet/egenskaben/rollen kan have |
| lovgrundlag | - | Valgfri | Angivelse af det lovgrundlag, som hjemler indsamlingen af data for objektet/egenskaben/rollen |
| eksempel | skos:example | Valgfri | Eksempler på anvendelse af objektet/egenskaben/rollen |
Værdierne angives i ren tekst
De tagged values, som nævnes i skemaet, er indeholdt i Grunddatamodellens stereotyper, som defineres i regel 5.6 UML-stereotyper skal anvendes.
Værktøjsunderstøttelse: I den MDG og base project, som distribueres af modelsekretariatet, er de relevante tagged values indføjet i stereotyperne i en separat gruppe - Grunddata:dokumentation - https://github.com/digst/grunddata-model-rules-tool-support
NOTE
Nogle domæner anvender store mængder metadata, som har til formål at indgå i brugervendt information om data (forklaringer til rapporter, hjælpetekst på web-sider etc.) Det vil ikke være formålstjenligt, at indlejre disse metadata i selve modellen, men de kan modelleres og distribueres som alle andre data og fordeles gennem den generelle data-arkitektur.
5.10 Referencer til klassifikationer, forretningsmodeller og organisationsmodeller bør anvendes
Regel
Referencer til ekstern information bør så vidt muligt være referencer til publicerede klassifikationer, forretningsmodeller og organisationsmodeller.
Rationale
De fleste data-objekter skal relateres til klassifikationer og andre typer af strukturer, for derved at give objektet kontekst og sammenhæng. For at styrke genbrugelighed og fremfinding, bør disse referencer pege på eksisterende, publicerede og strukturerede datasæt, som for eksempel FORM. Tilsvarende kan det være relevant, at pege på specifikke organisatoriske enheder - disse kan med fordel genbruges fra publicerede organisationsmodeller. Se endvidere afsnit 3.3.
Der eksisterer ikke på nuværende tidspunkt en infrastruktur, som understøtter sådanne strukturerede data. Derfor kan det være nødvendigt - eventuelt som en migrationsstrategi - at give data sammenhæng på simplere måder - for eksempel med reference til en liste over organisatoriske enheder. På et senere tidspunkt kan sådanne lister så importeres i infrastruktur-komponenter, og referencerne tilpasses.
Implikationer
Området er under udvikling, så derfor kan der ikke opstilles en udtømmende implikation. På samme måde kan denne regel ikke entydigt specificere konkret modellering eller danne grundlag for udvikling af konkret infrastruktur.
Anbefalinger:
| Ved angivelse af: | Brug: |
|---|---|
| Forretningsområde: | FORM:Anbefales generelt anvendt ved angivelse af fællesoffentligt forretningsområde. Anbefales specifikt anvendt som udfaldsrum for attributten ‘forretningsområde’ i regel 6.4. |
| Organisatorisk enhed: | ORGANISATION:Anbefales generelt anvendt ved referencer til organisatoriske enheder. Anbefales specifikt anvendt som udfaldsrum for attributterne registreringsaktør og virkningsaktør i regel 6.3. |
| Strukturerede data: | KLASSIFIKATION: Anbefales generelt anvendt ved referencer som kræver en mere kompleks struktur, end enumeration eller kodeListe kan understøtte. Anbefales specifikt anvendt som udfaldsrum for attributterne status i regel 6.2 og forretningsproces i regel 6.4. |
- No labels